What is Reinforcement Learning?
“…reinforcement learning seems to be a general learning algorithm that can be applied to a variety of environments; it may even be the first step to a general artificial intelligence.” –Antonio Gulli and Sujit Pal in Deep Learning with Keras
It seems like you hear about Reinforcement Learning, particularly Deep Reinforcement learning, everywhere these days. There is a lot of excitement around it, despite it not really being very effective just yet. [1]
So what’s going on and why are so people many interested in researching it?
One obvious answer is that Reinforcement Learning recently had a major victory with “Alpha Go”; the program that beat the world Go-Master, Lee Sedol. Growing up I always heard that someday soon computers would beat the world chess champion because that was simply a matter of getting more memory and processing power to allow a deeper search of possible moves. But we were also told that to beat a Go-Master would take "real intelligence" because there were far too many possible moves to do a computer search for the ‘best move.’
Well the first prediction turned out to be correct – it wasn’t long before Deep Blue beat Garry Kasparov (on May 11, 1997) in chess. But it wasn’t that much longer before computers went on to beat Sedol in Go (on Mar 15, 2016) as well. How was this possible? The answer is, Reinforcement Learning.
This series of posts will explain the theoretical basis for reinforcement learning and why it’s such an exciting field. In future posts I’ll give details on how to actually create a basic Q-Learner and demonstrate its ability to solve problems as diverse as solving a maze to buying and selling stocks -- all with the same basic algorithm.
My posts will be as follows:
Part 1: Overview of Reinforcement Learning and where it fits under the Artificial Intelligence / Machine Learning umbrellas
Part 2: The theoretical basis for Reinforcement Learning. Specifically, how clever computer scientists and mathematicians learned to drop the transition function from their equations, allowing them to use reinforcement learning on (theoretically) any real life function.
Part 3: And overview of how Reinforcement Learning, specifically a basic Q-Learner, really works. I'll give examples of the same Q-Learner solving grid world problems as well as how to apply it to making stock market long / short decisions.
Artificial Intelligence vs Machine Learning
First, let’s describe what we even mean when we banter about terms like Artificial Intelligence, Machine Learning, or Reinforcement Learning.
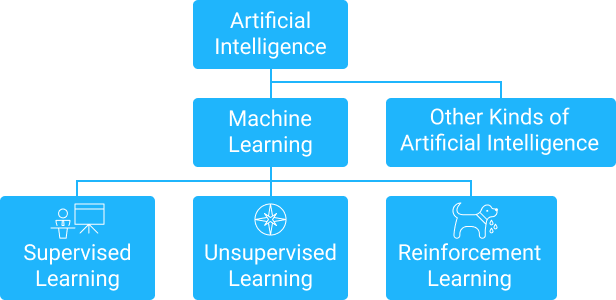
The graph above shows us the relationship between those terms.
Artificial Intelligence is an umbrella term to cover any algorithm that attempts to find best (or close to best) rational (i.e. ideal) solutions to problems -- particularly ones that would be intractable if you tried to use regular algorithms to solve them. For example, picking the best possible move in chess is an intractable problem that computers can't solve because the search space for chess moves is larger than the number of atoms in the universe. "Artificial Intelligence" is about coming up with a really good move that will (hopefully) beat an opponent even if it is not technically the "optimal" move.
Machine Learning is one family of algorithms under the umbrella of Artificial Intelligence. We call an algorithm "Machine Learning" if it learns from experience. A good example of the difference is Deep Blue -- that beat Kasparov at Chess -- and Alpha Go -- that beat Sedol in Go.
Deep Blue is an Artificial Intelligence algorithm that searched for a best move by cleverly figuring out how to search as many moves ahead as possible while ignoring moves that weren't worth considering any further. But think about how many possible moves there are in chess -- far more moves than atoms in the universe. So no computer nor algorithm could possibly search all the way to the end of the game. Instead, AI algorithms like this use a 'board evaluation' function to evaluate how good of a position a player is in given a specific board setup. A very simple such 'board evaluation function' would be to assign points for every piece. Even a beginner in chess knows that a pawn is worth 1 point, a queen worth points, etc. But adding up those points, you'd have a very basic board evaluation function.
Now given a clever search algorithm mixed with a clever board evaluation algorithm, you'd be able to play chess better than any human being without needing to search all the way to the end of the game. Just search, say, 5 or 6 moves ahead and then evaluate every possible board you can force the other player to. Pick the move that will get you to the best one. This is, in essence, how Deep Blue works.
However, Deep Blue's board evaluation function was created by hand. In essence, it was made up of human intelligence rather than machine intelligence. The "AI" part of Deep Blue was the search algorithm, not the board evaluation function. Because of this, Deep Blue never got better with additional play. I.e. it never "learned" anything. This is why Deep Blue is considered "Artificial Intelligence" but not "Machine Learning."
By comparison, Alpha Go did learn the more it played by improving it's board evaluation function as it played. Thus Alpha Go was not only Artificial Intelligence, but also used “Machine Learning” because it improved it's play as it gained more experience. [2] Interestingly, Alpha Go eventually got so good at evaluating the board, due to it's machine learning algorithm, that it could play at a professional level without searching more than a single move ahead. Use the Alpha Go Machine Learning board evaluation function with it's Artificial Intelligence search algorithm and it's pretty much game over for all human opponents.
Types of Machine Learning
Now just as artificial intelligence can be split into multiple sub-fields, likewise “Machine Learning” can be split into at least 3 kinds:
Supervised Learning
Unsupervised Learning
Reinforcement Learning
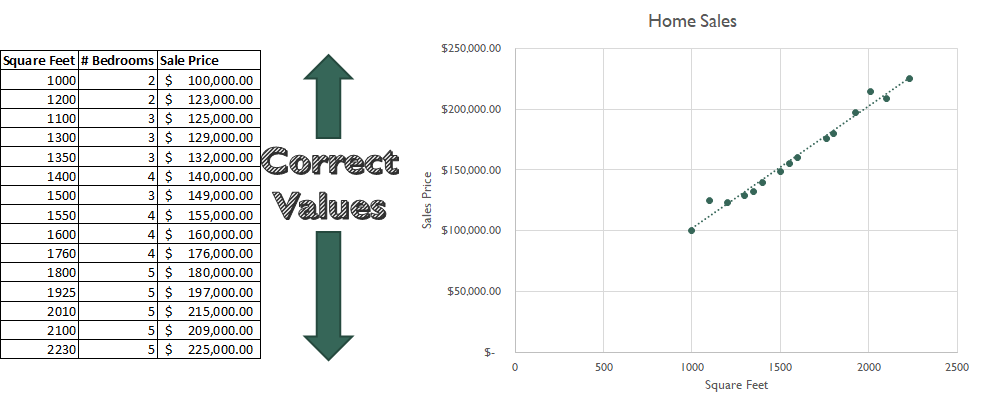
Supervised Learning is the most common – and best researched – form of Machine Learning. This technique involves showing an algorithm examples (or "samples") of a set of features. In my example above, I'm showing the algorithm examples of square feet and # of bedrooms of a house for sale. I also show the algorithm a set of outcomes, in this case the sales price for that house. The algorithm learns to predict the outcomes (sales price) from the features (square feet and # of bedrooms). Give a Supervised Learning algorithm more samples (more data about square feet and # of rooms vs sales price) and the algorithm will get better at predicting. That is to say, it learns with experience.
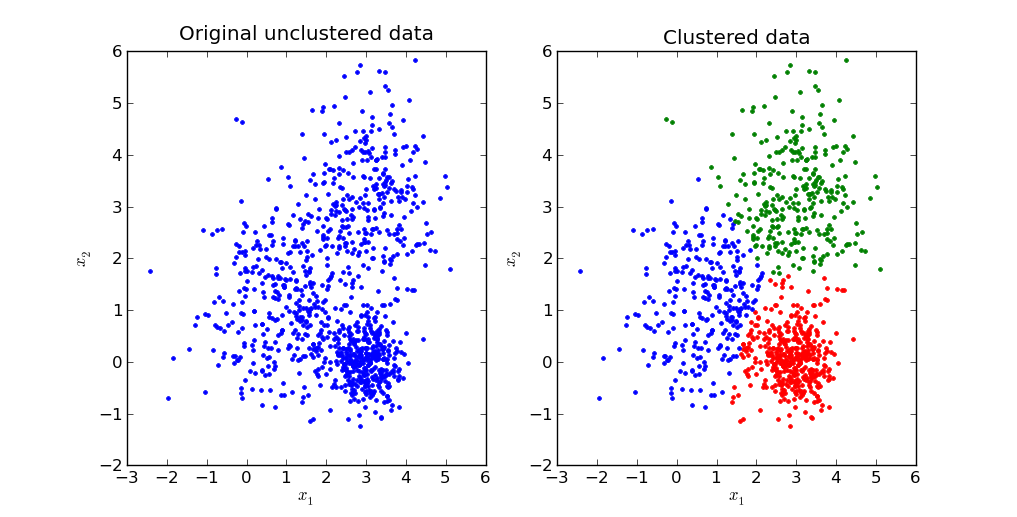
By comparison, Unsupervised Learning has no specific outcomes it’s trying to predict. For example, imagine you had the following data points and you wanted to see how they clustered together. Unsupervised learning might cluster them into 3 clusters something like these graphs to the right.
Characteristics of Reinforcement Learning
So what makes Reinforcement Learning different from Supervised and Unsupervised forms of Machine Learning. The main characteristics of Reinforcement Learning that distinguish it from regular Machine Learning are:
Exploration
Delayed Rewards
Continuous Learning
So consider Supervised Learning where you have a training phase where you train a model (e.g. to predict sales prices of homes) and only after this training phase do you use the algorithm to make predictions. However, the algorithm never improves after that. By comparison, Reinforcement Learning continually improves as it gains experience. In other words, Reinforcement Learning can "continuously learn" whereas Supervised Learning is either learning a model or using the model, but not both.
Reinforcement Learning also relies heavily on Exploration with Delayed Rewards. This matches real life much better than Supervised Learning. Suppose, for example, you created a machine learning algorithm to tell you if an image is a hot dog or not a hot dog. Now the world does not comes with hot dog labels to learn from, so a human ‘expert’ in hot-dog-ness needs to first create a training set of examples of a hot dog for the algorithm to learn from.
By comparison, Reinforcement Learning learns from real life rewards that the environment naturally provides as feedback. For example, an algorithm that buys and sells stocks can learn whether or buy or hold based on the stock market providing it ‘feedback’ or 'rewards' of how much money was actually gained or lost. This removes the need for the human expert to first label the world.
The Markov Decision Process (MDP)
So how does Reinforcement Learning really work? Reinforcement Learning is a set of techniques that can solve what is called a Markov Decision Process. I’m going to now explain the formal definition of the Markov Decision Process as it will help explain why Reinforcement Learning can solve it. [3]
A Markov Decision Process is formally defined by the following variables:
S = States agent can be in
A = Actions agent can take
At time t, the agent senses current state: St
Agent takes action At
The environment gives reward Rt in response and moves agent to state St+1:
δ(St, At) = St+1(State Transition Function)
r(St, At) = Rt (Reward Function)
Putting this into plain English isn’t as bad as it first appears. It’s basically saying that to use Reinforcement Learning, we must be able to take a real world problem and define the problem as a series of states (S) in which we can take certain actions (A) at a specific time (t) and that in return the environment will then change or adapt to our actions and return to us some sort of reward.
Don’t be thrown off by functions with fancy Greek symbols like δ(St, At) which is our State Transition function. We traditionally use the Greek letter "delta" (i.e. δ) to represent the changes that take place, i.e. the transitions that take place.
In actuality, this is pretty simple. If you’re in a State at time t (i.e. St) and you take action A at that time (i.e. At) of course you’d expect things to change. Maybe the thing that changes is nothing more than your location! So imagine a robot that is in the hallway. Its current state is that it’s located in the Hallway, so St = Hallway. The robot then moves north because it wants to go to the Lobby. "Moving north" is it’s action at that time, so At = "Move North"
The somewhat less intuitive part is the reward function, r(St, At). Let's say our goal was to get the robot to move to the lobby. So we might give it a 'reward function' that says "if in State = Lobby then give a reward of 100 points, otherwise give no reward." Now realistically, the robot can't just suddenly appear in the lobby to get its reward. Perhaps it has to first rotate itself, then move forward towards the lobby, then maybe rotate itself a bit more, etc. until it successfully gets to the lobby and receives it's desired reward of 100 points.
As we’ll see, the reinforcement algorithm will smartly figure out what states and actions get it closerto its desired goal. (This is the Delayed Rewards concept I mentioned above.) Even though it has to take a series of actions to get to its goal, it learns which actions at which states get it closer to the goal and which get it further from the goal. Then using this information (which we call “Utility”, see below) it plans out how to move itself to the goal.
This is all there is to the Markov Decision Process. So it's actually fairly simple, conceptually. The hard part was figuring out how to make it all mathematically formalized so that we can program a computer to solve it.
The Markov Assumption
There is one key assumption here that falls out from the above description but isn’t immediately obvious. Note that there is no history being tracked, just a current state. So the robot does not track where it used to be, it simply assumes that all the information it needs is contained in the current “State information.”
This might seem like a huge constraint at first, but really it’s not quite as bad as it first appears. For one thing, you can pretty much define ‘current state’ however you want. If you really want to ‘promote’ past state info to be part of the currently tracked state, you can.
Also, one can (correctly) argue that all of physics – and thus all of reality – is in fact a Markov Decision Process. The laws of physics don’t care about the past either. Given physics equations and a description of a particle’s current direction, velocity, and acceleration, and you can predict where the particle is going to be next. You don’t need a history of its past trajectory to calculate that.
Simple Example of a Markov Decision Process
Okay, let’s make this more concrete. Let’s make a Very Simple Maze™ for a robot to run through:
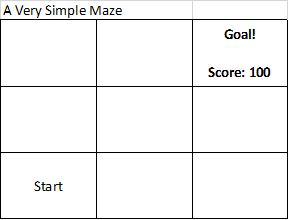
Okay, this is such a simple maze it isn’t even a maze! It’s just 9 squares (our States!) that the robot might find itself in. No walls or anything else blocking it. The lower left square is where the robot will start and the upper right square is where it wants to move to – i.e. where it will receive the 100 points reward.
So we know we have only 9 states here, but how many actions do we have per state? For simplicity, let’s assume the robot can only move up, down, left, or right. So there are 4 actions per state. [4] This effectively makes our legal actions something like this.
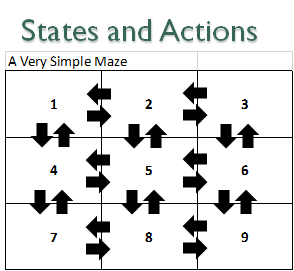
Now intuitively this diagram makes obvious sense. It pretty obvious that if you are in state 7 and you move up, you’ll now be in state 4. Etc. But computers are stupid, so how might you formalize that into a Transition Function? Well how about this table to the right as an approach?
Basically I just made a table where I list every possible state enumerated against every possible action and I then list what the new state will be should you take that action in that state. Note how "state 7 - action Up" moves us to state 4 – exactly as is obvious. This is going to be our simple "Transition Function" for our Very Simple Maze™.
And how about the reward function? Even easier. Make a table that shows that every state has a reward of zero except state 3. Set that to a reward of 100. I won't even draw this one for you because it's so simple.
Now in real life, on a reward function, we’d probably want to assign a small negative reward to non-goal states, say -1 points. This forces the robot to get serious about finding the goal to save its reward. But for our simple example, we won’t even do that much and we'll just set all non-goal states to a reward of zero.
So now that we’ve defined the Markov Decision Process, and shown how to apply it to a really simple example. But how would we teach our robot to solve this maze?
Dynamic Programming to the Rescue
Let’s pretend we had a magic algorithm that could ‘solve’ this decision process and find the optimal answer every time. That would be really useful because then we could just first take any problem in existence, figure out how to map it into the Markov Decision Process (which, at least in theory, all real life problem can be mapped to MDPs), and then apply our magic algorithm and – voila! – we’ll have a solution to our problem!
So there was this super smart guy, named Richard Bellman, that did in fact come up with a magic algorithm (of sorts) that could solve any Markov Decision Process – at least in theory. That algorithm is called Dynamic Programming. [5]
Now its outside the scope of this blog post to describe Dynamic Programming, but imagine you took our Very Simple Maze™ and did something like this:
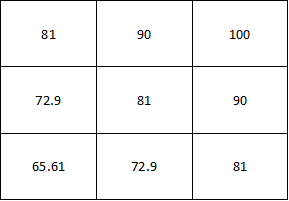
What I’m doing here is I’m starting with the reward of 100 in the upper left corner (as our Reward function tells us!) and I’m giving a value to every other square depending on how close it is to that reward. Or putting it in more economic terms, I’m discounting for the future. I’m saying if state 3 (the goal) is worth 100 points for being in that state, then states 2 and 6 should have a higher utility then, say, states 4 and 8. Why? Because states 2 and 6 are only one square away from the reward whereas states 4 and 8 are two squares away.
The essence of dynamic programming is that I use the transition function and reward function, query them, and then calculate a utility for each state based on how close I am to the reward.
I note here the very important distinction between Reward and Utility. The robot only receives a reward in our current MDP design for being in state 3 (i.e. the upper right hand corner). But every state can have a calculated utility based on how close it is to the reward. Note that this means, for example, that state 6 has a utility of 90 but a reward of 0.
After our magic Dynamic Programming algorithm calculates the utility for each state, then the next step is to calculate a Policy for each state. Imagine doing something like this:
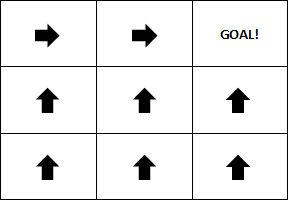
Can you see the value of our policy here? No matter what state you find yourself in, you just take the move that it says is optimal and you'll get to the goal (and the reward) as quickly as possible. Neat, huh? We call this an Optimal Policy because it's a policy that always gets you the highest reward possible for your state.
Can you see how to compute the Optimal Policy from the Value function that came before it? You basically just select the move available in that state that moves you to the highest possible Utility value. Use that logic for every single state and you’ll end up with a ‘best policy’ for each state.
But Wait! What if I Don’t Know the Transition Function?

Photo Credit: Photo Credit: Designed by www.vecteezy.com
But the underlying assumption of Dynamic Programming is that I know what the Transition and Reward functions are. Sure, in our simple of example, that’s easy to work out. But how likely am I to know, say, the transition function of the stock market? Oops. I guess Dynamic Programming isn’t such a magic algorithm after all!
If only we could come up with a way to form an optimal policy without knowing the transition and reward function… if only…
That will be the subject of my next post.
Link to original presentation slide show.
Notes
[1] Alex Irpan, a Google employee on their Brain Robotics team, recently went as far as saying “Whenever someone asks me if reinforcement learning can solve their problem, I tell them it can’t. I think that is right at least 70% of the time.” He goes on to blog about why he feels that is currently the case despite also claiming that reinforcement learning is the future.
[2] Just to be clear here, in fact both Deep Blue and Alpha Go used searching techniques to find the best move, of course. But Deep Blue was primarily a searching technique in that its board evaluation function was handwritten and thus was really just a regular human built algorithm. Alpha Go used Reinforcement Learning to evaluate the board and thus mixed Artificial Intelligence (searching) and Machine Learning (Reinforcement Learning) together. Searching alone was insufficient with Go because Go has far too many possible moves and no easy way to evaluate if you're ahead or behind just by looking at the board. It's not like chess where the number of pieces you have remaining gives a pretty good picture of who is ahead or behind. Human experts get very good at intuiting how good their position is and it required Machine Learning to let a computer duplicate that intuition.
[3] This discussion is largely taken from Tom Mitchel's book, Machine Learning.
[4] So all my examples actually show no action for a move into a wall. But assume that's legal, but useless because you just end up back at the state you're already in.
[5] Dynamic Programming was so named before “programming” was the term used to label what we did on a computer. So it actually has nothing to do with computer programming and is actually a mathematical technique.